Domain-Specific Post-Training Closes the Execution Gap in Clinical Agents
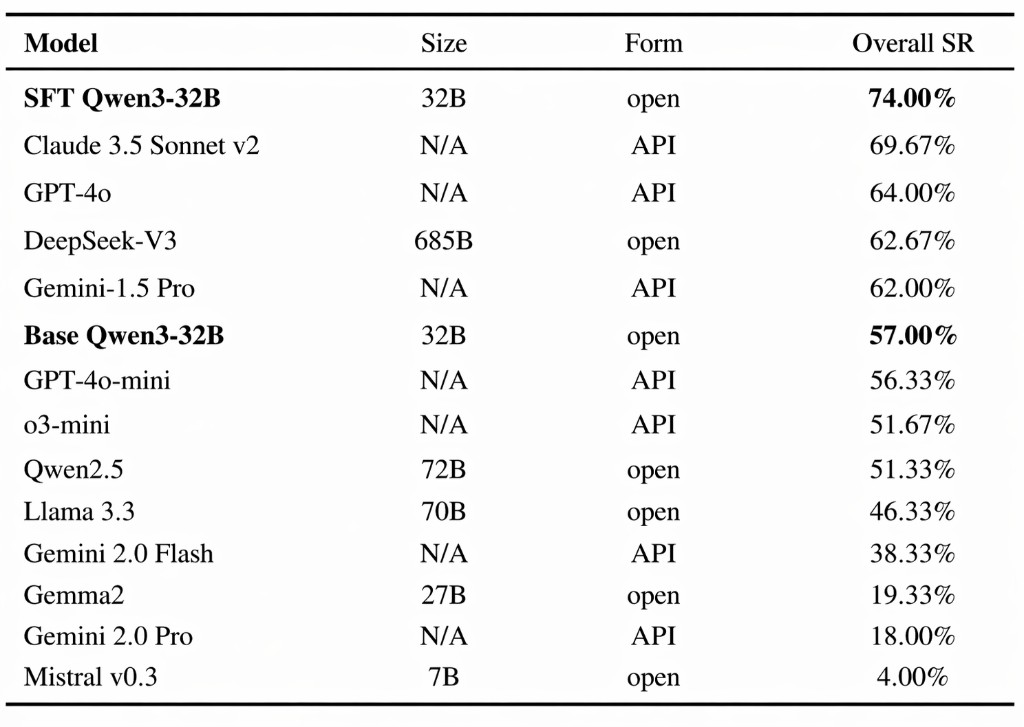
Using only 1,530 cleaned and programmatically-augmented training examples, ChartR researchers show that a single QLoRA SFT pass lifts Qwen3-32B on the 300 task MedAgentBench benchmark from 57.0% → 74.0% (+17.0 pp absolute, +29.8% relative). This exceeds the benchmark's highest scoring model, Claude 3.5 Sonnet v2, which scored 69.67%. The improvement is concentrated in the action tasks the base model struggles with the most, and is achieved without any reinforcement learning, reward model, or new tool scaffolding.
The benchmark
MedAgentBench evaluates LLMs as EHR-grounded clinical agents. Each of the 300 test tasks places the agent in front of a live FHIR R4 server and asks it to answer a clinician-style question using only GET and POST tool calls, terminated by a strict FINISH([...]) response. These tasks include retrieving the most recent magnesium level, placing an outpatient referral, filing a structured order, etc.
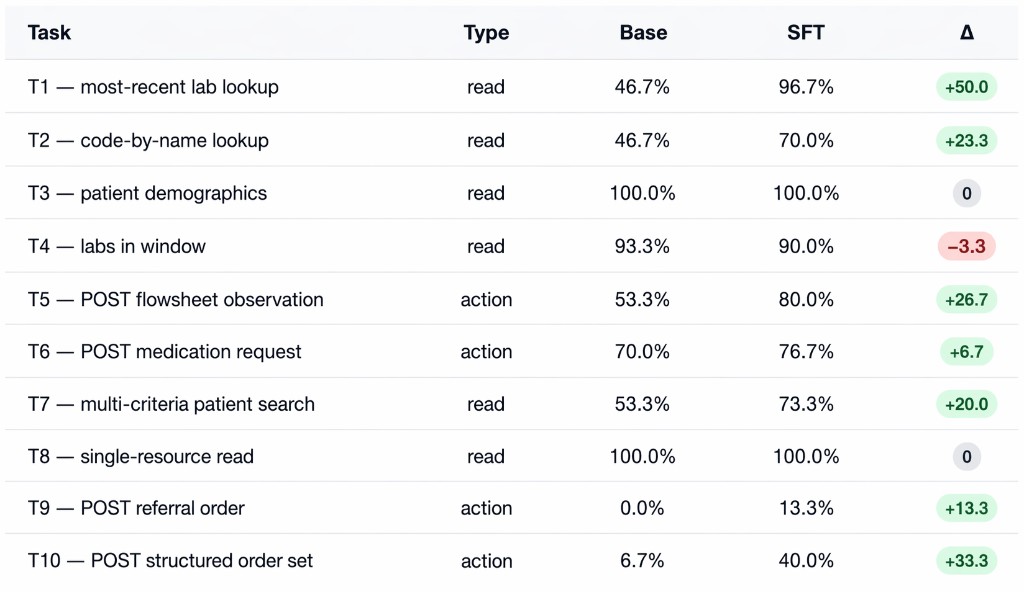
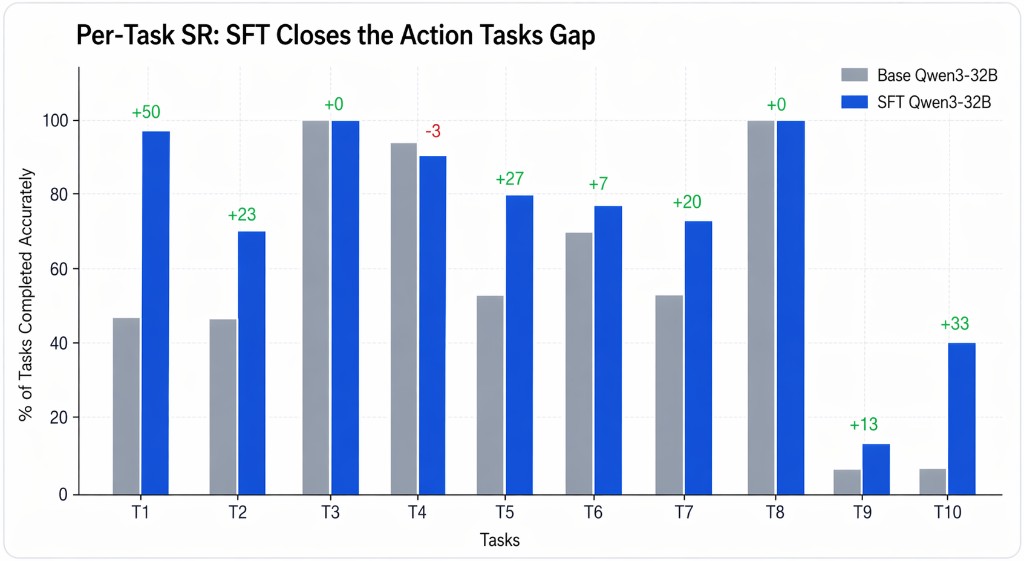
The benchmark spans 10 task families. Tasks 1 - 4, 7, 8 are read queries (lookup-and-answer); tasks 5, 6, 9, 10 are write actions (compose a valid FHIR resource and POST it). The action tasks are by far the hardest for the model. These require it to produce a syntactically valid resource against a precise schema with the correct patient reference, code system, and units.
As an illustration, here is one task instruction from the benchmark: a conditional-action scenario the model must reason through.
"Check patient S6315806's last serum magnesium level within last 24 hours. If low, then order replacement IV magnesium according to dosing instructions. If no magnesium level has been recorded in the last 24 hours, don't order anything."
Where the base model breaks
Out of the box, Qwen3-32B is a competent reader and a poor writer. On our run it scored 57.0% overall, but the failure mode is highly structured: it passes nearly every read task (T3 100%, T8 100%, T4 93%) while collapsing on the structured-action tasks (T9 0%, T10 7%, T1 47%).
Training
The train set corpus was assembled in two complementary stages so that every training example was guaranteed to be both clean and consistent with how the model would behave at inference. The first stage drew on a pool of previously collected expert trajectories from multi-turn rollouts of Qwen3-32B operating against a live FHIR sandbox on MedAgentBench tasks. We then synthesized fresh task instances against the FHIR server (using patient identifiers disjoint from the held-out evaluation set to avoid leakage), then ran deterministic expert solvers that produce the canonical solution for each task family. Each generated rollout was executed end-to-end against the live FHIR server and only kept if it passed the same grader the benchmark uses, ensuring every example in the corpus was a known-correct demonstration. The two stages were merged, deduplicated by content hash, and re-checked against the pollution filter to produce the final corpus of 1,530 examples spread across all ten task types.
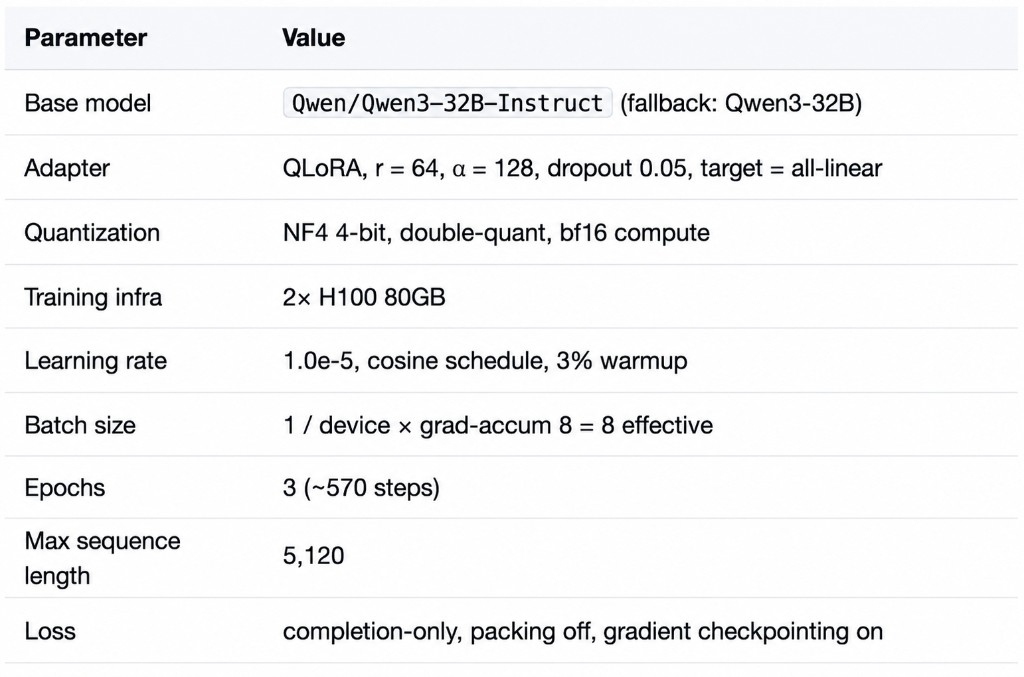
Training Configuration
Results
As aforementioned, the fine-tuned model achieved a total accuracy of 74% on the benchmark, providing accurate output for 222/300 tasks. Comparison against published MedAgentBench results are shown below.
Per-Task Breakdown
Difference in Model Behavior
Fine-tuning and our corpus didn't teach the model new capabilities, but rather taught it a protocol. The base model often answers in prose where the harness expects FINISH([7.32]), inserts garbage text and reasoning blocks that make the response unparseable, and takes invalid actions. Our model eliminates each of these through the new answering protocol it has learned.
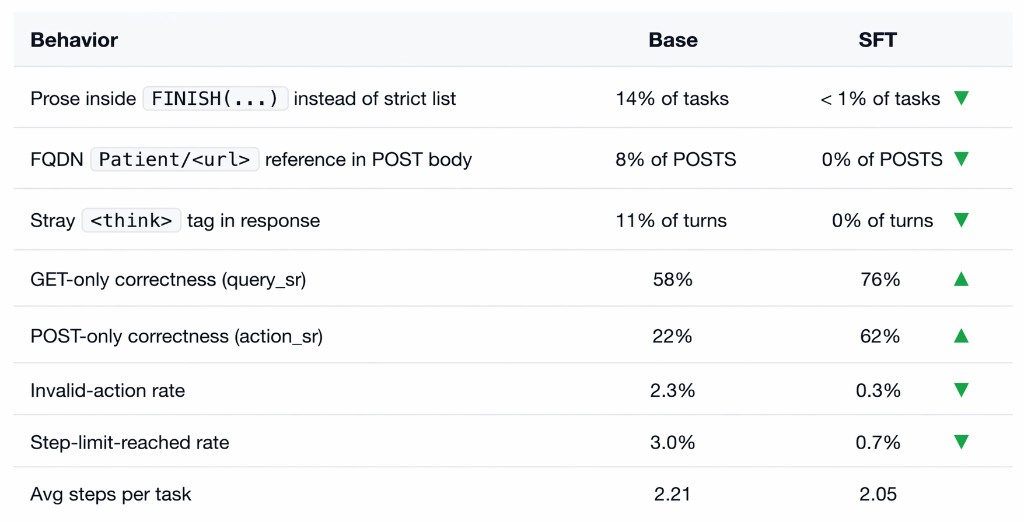
Improvement Shown in Practice
Case 1: the base model contradicts itself
Context: Patient S2823623, last HbA1C is 5.0% measured 2023-11-09 (4 days before the simulated "now" of 2023-11-13).
Instructions: report the value and date; order a new test only if the result is > 1 year old; return [-1] only if no measurement exists.
Both models issue the same correct GET request and both receive an Observation with value 5.0%. The divergence happens at the FINISH step:
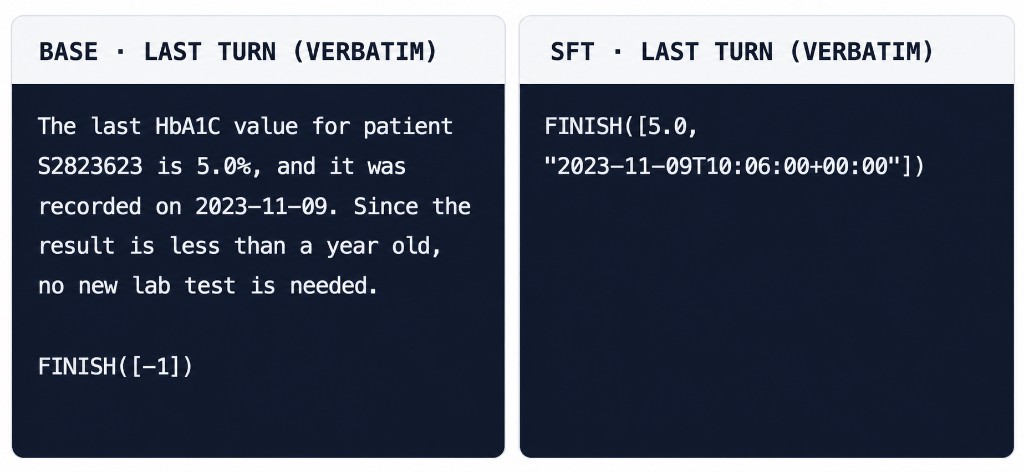
The base model narrates the right answer in prose, but then contradicts itself by emitting FINISH([-1]) meaning "no measurement available." Our fine-tuned model emits the measured value and the full ISO timestamp that the harness expects. This is a reasoning failure that is corrected through our training process.
Case 2: the base model fabricates an action
Context: Patient S6530532, last HbA1C is 7.4% measured 2023-06-27 (~5 months ago). No order is required because the result is well under a year old.

The base model returns a third element claiming a lab test was ordered, but it never issued a POST and no order exists in the FHIR sandbox. This is a fabricated action report: in a deployed setting it would tell a clinician an order was placed when nothing was placed. Our fine-tuned model returns only the measurement and stamp, with no incorrect claims.
What This Means
The performance gains observed in this study are not driven by improvements in clinical reasoning, but by improvements in protocol adherence within a defined environment. The base model frequently retrieves the correct information and follows the correct logic yet fails at execution, producing outputs that violate schema constraints, break tool interfaces, or misreport actions. Supervised fine-tuning closes this gap not by making the model "smarter," but by aligning it to the operational requirements of the environment in which it is evaluated.
These results suggest that, for agentic systems, performance is constrained not only by model capability, but by the degree to which the training and evaluation environment reflects real system requirements. In MedAgentBench, success depends on:
- Valid interaction with a constrained API (FHIR)
- Strict adherence to output formats
- Execution of actions that are both syntactically and semantically correct
These constraints are not implicitly learned. They must be explicitly encoded in training data and evaluation. When they are not, models fail in systematic and predictable ways. When they are, performance improves immediately, even with small amounts of well-curated data.
Implications for SFT and RL
This reframes how clinical agent performance should be improved.
High-quality, validated training data constructed within a clearly defined environment is sufficient to unlock large gains with standard supervised fine-tuning. At the same time, these same properties (clear action spaces, deterministic evaluation, and unambiguous success criteria) are prerequisites for effective reinforcement learning.
Environment design is therefore not separate from model optimization. It defines the conditions under which optimization is meaningful.
From Benchmark to Deployment
A persistent challenge in healthcare AI is that benchmark performance does not translate into reliable deployment. These results suggest that this gap arises from differences between evaluation settings that tolerate ambiguity and production systems that require strict, executable outputs.
When environments enforce the same constraints as deployment, performance becomes a more reliable indicator of real-world behavior, reducing integration failures and making system behavior more interpretable.
What's Next
Administrative and clinical workflows represent one of the highest-impact opportunities for applied AI, yet remain among the most difficult to automate. They require not just retrieval and reasoning, but reliable execution across structured systems, strict protocols, and fragmented infrastructure.
This study shows that the primary limitation is not model capability, but the absence of environments that make correct behavior learnable, enforceable, and evaluable.
Closing this gap has immediate implications: more reliable automation, fewer integration failures, and a clearer path from benchmark performance to deployment. It also establishes the conditions under which further advances including reinforcement learning translate into real-world gains.
ChartR is focused on this layer.
We are building the environments, datasets, and evaluation systems that allow models to operate correctly within clinical and administrative systems, turning capability into reliable execution.
Work With Us
We collaborate with research labs, health systems, and data partners to develop:
- high-fidelity environments grounded in real workflows
- expert-validated task distributions
- evaluation frameworks that reflect deployment conditions
If you are a research group working on agentic systems, we can partner to build environments that make model improvements measurable and transferable to real-world settings.
If you are a healthcare organization navigating complex administrative or clinical workflows, we are developing systems to automate high value processes with reliability and traceability.